
The team that started HighByte picked an open spot called DataOps in the OT/IT pantheon that I felt was today’s sweet spot. The IT companies introduced me to DataOps (the next thing past DevOps, I guess). The application looked, shall we say, useful. HighByte is up to version 1.4 just released and has many applications in the wild already. It is well worth your time checking out.
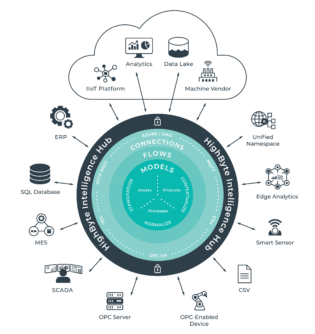
HighByte announced the release of HighByte Intelligence Hub version 1.4. HighByte Intelligence Hub is an Industrial DataOps solution enabling manufacturers to streamline their data architecture and reduce time to deploy new systems. The software supports open standards and provides Operations Technology (OT) teams with the flexibility to merge, prepare, and deliver industrial information to and from IT systems without writing code. With its latest release, HighByte Intelligence Hub now supports complex, multi-value sets of data, a broader range of disparate data sources, flow consolidation, and additional security features.
“HighByte Intelligence Hub enables me to easily model data—adding context, segmenting, and publishing data to the unified namespace”, said Tim Burris, a software architect at Ectobox. Ectobox is an industrial intelligence solutions company specializing in data-driven manufacturing, ISA-95, and software consulting and development for their clients. “The time HighByte Intelligence Hub has saved me is incredible. I’m using the flow capabilities, updated SQL connecter, and REST input to reduce custom code and deliver a maintainable integration solution to our clients. It’s a game changer.”
HighByte works with a network of system integrators and international distributors to take HighByte Intelligence Hub to market, serving customers in a wide variety of vertical markets including biotechnology, packaging, industrial products, and academic labs. “This release focused on meeting the needs of our customers and partners with a more sophisticated solution that can handle complex data,” said HighByte CEO Tony Paine. “HighByte Intelligence Hub is ready to support Edge-to-Cloud and Cloud-to-Edge use cases.”
HighByte Intelligence Hub is an Industrial DataOps application designed for scale. The latest release includes support for complex data sets that can be processed through HighByte Intelligence Hub’s modeling engine, transforming and contextualizing information at high volumes. The release also includes new codeless connections for CSV files and JDBC drivers, significant improvements to existing SQL, MQTT, and OPC UA connectors, multiple flow inputs and outputs, array handling, and REST templates. Security enhancements include secure connections over MQTT with SSL encryption as well as payload encryption and usernames and passwords for OPC UA connections.
To learn more about the release and see a live demonstration of the software, please register for the “Unified Namespace and Cloud-to-Edge: New Use Cases for Industrial DataOps” webinar on April 14, 2021 at 11AM ET.
I copied the information below from the HighByte blog written by Aron Semle to add more context and user ideas to the product news: https://www.highbyte.com/blog/new-use-cases-highbyte-intelligence-hub-version-1-4-is-here
Highlights & Use Cases
- Use Multiple Flow Inputs and Outputs. Let’s say you’ve created a “boiler” model to model the ten boilers you have at your facility. Now you can create a single flow that sends data for all ten of the boilers to an AWS IoT Core topic or all the boiler data to multiple outputs, like a REST endpoint for debugging and Azure IoT Hub for production.
- See Your Data. Now you can easily create and test any input in the UI, allowing you to see what data and schema the input returns. Not sure where that “amps” attribute was in that JSON payload? Simply expand the input in the expression builder and see all the data and schema right in the UI.
- Work With Arrays. Arrays are everywhere, from OPC UA arrays representing set points in the PLC, to an array of JSON objects representing motor running hours from a maintenance system. HighByte Intelligence Hub now supports inputting and outputting simple and complex array types. You can index arrays in expressions, slice them, dice them, and even build arrays out of primitive OPC UA tags.
- Read CSV Files. Many older industrial devices, especially testing equipment, write their data to a CSV file. This new input makes it easy to read one or more CSV files from a directory. Files can be static, or the input can index files, reading them in chunks and moving them to a completion directory when done.
- Get More From Your OPC UA Connections. OPC UA now supports encryption and username and password. The connector also supports outputting a model to a tag group (i.e., multiple tags), making getting modeled data into an OPC UA server even easier.
- Move SQL data Into and Out of Your UNS. You can now read multiple rows from a SQL table, run them through a model to do things like change the column name or add in new data, and output them to MQTT as an array of JSON objects representing each row. This makes getting SQL data into your UNS easy. The SQL connector output also now supports table creation, so you can connect an MQTT input into the UNS, subscribe to a topic, and output the data model directly to a SQL table to review data locally. SQL outputs can also call stored procedures or log data as JSON in cases where the model schema isn’t finalized.
- Leverage REST Templates. Do you need to get data into InfluxDB using their line protocol? Or Elastic Search? The REST output now allows you to transform the default JSON output to any format you need, including XML. This makes integration with REST based interfaces easy and flexible.
- Enable Cloud-to-Edge with MQTT. MQTT now supports inputs and secure (TLS) connections, allowing you to connect to MQTT brokers like AWS IoT Core. This enables “Cloud-to-Edge” use cases, where machine learning alerts generated in AWS can be sent back down to HighByte Intelligence Hub, transformed via modeling, and then output to protocols like Sparkplug, making the data immediately available in any Sparkplug-enabled SCADA system like Ignition. Another common use case with a similar data flow is streaming sensor data to AWS IoT Core from third-party sensor providers (i.e. LoRa sensors). This data can be pulled in, modeled, and output to the SCADA system using HighByte Intelligence Hub.




